How to connect Claude to PubMed (step-by-step setup)
Set up the PubMed connector in Claude for verified medical literature search — enable it, query it, and check every PMID so citations are real, not hallucinated.
Jun 22, 2026
Laszlo Szabo 

Literature search is now the most common physician AI use case, with 35% of doctors using AI for this purpose (Doximity, 2026). Yet when researchers tested GPT-4o on mental health literature reviews, 56% of citations were fabricated or contained errors — wrong DOIs, wrong authors, or references to papers that do not exist (Linardon et al., JMIR Mental Health, 2025). The gap between enthusiasm and reliability is where careful engineering matters.
In a previous post, I described a manual workflow for using Claude’s PubMed connector to search the medical literature without hallucinating citations. That workflow relies on five habits — PICO framing, retrieval-not-recall, paste-don’t-summarise, structured synthesis, and verification. They work. But they depend on the clinician remembering every step, every time.
This post describes how I codified that manual workflow into a reusable Claude skill that automates evidence gathering for medical literature search, with built-in safeguards that run whether you remember them or not.
A Claude skill encodes the principles from manual AI-assisted literature search — generation-vs-retrieval separation, dual-source searching, structured verification — into a repeatable pipeline. With 81% of physicians now using AI (AMA, 2026) but 71% citing accuracy concerns (Doximity, 2026), the reference ledger and automated DOI verification are what make this approach safe for clinical use.
Eighty-one percent of US physicians now use AI in clinical practice, more than double the 38% reported in 2023 (AMA Physician Survey, 2026). Thirty-nine percent use it specifically for research summaries — up 26 percentage points in a single year. AI adoption is no longer the question. Safety at scale is.
The manual workflow from my previous post works well for a single literature search. But it is a conversation each time. Nothing is codified. Nothing is auditable. Nothing is repeatable. The clinician must remember to frame questions in PICO format, to use retrieval rather than recall, to verify DOIs against PubMed metadata. Miss one step at the end of a long day, and you risk citing a paper that does not exist.
A Claude skill solves this by encoding the workflow into a custom instruction set with enforced guardrails. Think of it as the difference between a checklist pinned to the wall and a checklist built into the system. The skill defines the search strategy, mandates dual-source searching, builds the reference ledger automatically, and runs verification before producing any output. The clinician’s job shifts from remembering the process to appraising the results — which is where clinical judgement should be spent.
About half of clinical guidelines become outdated within 5.8 years (Shekelle et al., JAMA), so keeping up with the evidence is not a one-off task. A skill that can be run repeatedly, producing consistent and auditable output each time, is more valuable than a manual workflow that only works when the clinician has time and headspace to execute it perfectly.
A Claude Code skill is a SKILL.md file that acts as a custom instruction set for a specific task. When you trigger the skill — by typing something like “search for evidence on CMV prophylaxis” — Claude Code loads the SKILL.md as its prompt and follows the workflow defined inside it.
The file has two parts. The YAML frontmatter controls activation and model selection:
---
name: literature-search
model: opus
effort: max
description: >
Search PubMed, Scholar Gateway, and national guideline websites
for current clinical evidence on a given topic...
---Setting model: opus forces the most capable model regardless of the user’s default. Setting effort: max enables extended thinking, which matters for multi-step reasoning across dozens of papers. The description field doubles as a trigger matcher — Claude Code reads it to decide when to activate the skill.
The body of SKILL.md is the full prompt: the six-step workflow, the search strategy rules, the verification checklist, and the output format specification. It is not a configuration file. It is a detailed set of instructions, written in plain English, that the model follows step by step.
Reference files — a PubMed search guide, a document template — live alongside SKILL.md but are not loaded automatically. The prompt tells the model when to read each one, so context stays lean until the information is actually needed.
The repository is intentionally small:
literature-search/
├── SKILL.md # The prompt — 6-step workflow
├── references/
│ ├── pubmed_strategy.md # PubMed query construction guide
│ └── evidence_summary_template.md # Output document structure
├── assets/
│ └── reference.docx # Pandoc styling template
└── evals/
└── evals.json # 7 test scenariosSKILL.md is the orchestrator. It defines the entire workflow and coordinates when to read each reference file. During Step 3 (searching), it reads pubmed_strategy.md for guidance on constructing Boolean queries with MeSH terms and publication type filters. During Step 5 (writing), it reads evidence_summary_template.md for the exact document structure — section headings, citation format, mandatory transparency disclaimer.
Reference files are injected context, not configuration. The model calls the Read tool on them at the right moment. This keeps the initial prompt smaller and means each file is loaded only when its content is relevant to the current step.
The working ledger (_working_ledger.yaml) is the skill’s memory externalisation. After every PubMed API call, the model writes the returned metadata — PMID, DOI, title, authors — to this file immediately, in the same turn. Before generating any output, it re-reads the ledger from disk rather than relying on what it remembers from context. This was added in version 1.4.0 after a real failure where a DOI differed by three characters (blood.2018894368 vs blood.2018894618) because the model wrote from memory instead of copying from the API response. Externalising memory to a file eliminates this class of error entirely.
Evals (evals.json) contain seven test scenarios covering different clinical domains — from transplant immunology to haematology to cardiology — plus a scope guardrail test that checks the skill refuses overly broad topics like “cancer treatment” and asks the user to narrow down.
PubMed contains over 36.5 million citations and adds 1.57 million annually (NLM, FY2023). No single search strategy catches everything relevant. The skill addresses this by using two complementary search engines with fundamentally different approaches.
PubMed MCP is the structured engine. It searches using MeSH terms, Boolean operators, and publication type filters. When the skill needs to find randomised controlled trials on a specific drug regimen, it constructs a query like:
rituximab AND "ABO incompatible" AND (kidney OR renal) AND transplant
AND (Review[pt] OR Meta-Analysis[pt] OR Randomized Controlled Trial[pt])This returns precise, filterable results with full metadata — PMIDs, DOIs, author lists, abstracts. PubMed is excellent at finding what you know to look for.
Scholar Gateway is the semantic engine. Instead of keywords, it takes natural language clinical questions and searches full-text passages across peer-reviewed literature:
What is the optimal isoagglutinin titre target before
ABO-incompatible kidney transplantation based on recent evidence?Scholar Gateway returns the actual relevant text passages with DOIs and citations. It finds papers that keyword searches miss entirely — particularly those that use different terminology or frame the question differently.
This is not “search twice for the same thing.” The skill formulates different query types for each engine. In a recent search, Scholar Gateway identified four papers the PubMed keyword search had missed, all directly relevant to the clinical question. The results are de-duplicated by DOI, so each paper appears once in the final reference list regardless of which engine found it.
When Deakin University researchers asked GPT-4o to write six literature reviews on mental health topics, 20% of the 176 citations were entirely fabricated and a further 45% of the real ones contained bibliographic errors — wrong DOIs, incorrect dates, or invalid identifiers. Combined, 56% of all citations were fabricated or inaccurate. Worse, 64% of the fabricated DOIs resolved to real but completely unrelated papers — a reader clicking the link would find an actual paper, just not the one being cited (Linardon et al., JMIR Mental Health, 2025). This is the most insidious form of hallucination: it looks correct even when you check.
In the manual workflow, preventing this relies on discipline — the five habits. In the skill, it is structural. The reference ledger is a data store built incrementally during the search phase. For every paper the skill plans to cite, it calls PubMed’s get_article_metadata and records each field exactly as returned:
REF_ID: 12
PMID: 31006573
DOI: 10.1016/S0140-6736(18)32091-9
AUTHORS: Scurt FG, Ewert L, Mertens PR, et al.
TITLE: Clinical outcomes after ABO-incompatible renal
transplantation: a systematic review and meta-analysis
JOURNAL: Lancet
YEAR: 2019
KEY_FINDING: Graft survival equivalent to ABO-compatible transplants
after 5 years; early mortality elevated (OR 2.17 at 1 yr)
SEARCH_TOPIC: ABO-incompatible kidney transplantation outcomesThe critical design decision: the final reference list can only be generated from this ledger. No ledger entry means no citation in the document. DOIs are opaque identifiers — there is no way to guess or reconstruct one from a paper title. If the model writes a DOI from memory rather than copying it from PubMed metadata, it will almost certainly link to the wrong paper or a dead URL. The ledger eliminates this failure mode entirely.
Abstracts give headlines. They rarely include the methodology details, subgroup analyses, or dosing specifics needed to evaluate whether a paper actually supports a recommendation. The skill selectively retrieves full text for 5–10 key papers via PubMed Central’s get_full_text_article.
Full text retrieval is targeted, not exhaustive. The skill prioritises papers that directly support or contradict a key finding, systematic reviews where subgroup data matters, and studies where the abstract is ambiguous about sample size or effect size.
When full text is not available — many papers sit behind paywalls — the skill falls back gracefully to the abstract combined with any relevant passages Scholar Gateway retrieved from indexed full text. Between these two sources, there is usually enough to assess the paper’s relevance and quality.
Seventy-one percent of physicians cite accuracy and reliability as their top concern about AI tools (Doximity, 2026). The manual workflow addresses this with a habit: “verify key statistics before citing.” The skill formalises it as an enforced checklist that runs before any output is delivered.
The verification step includes five checks:
10. and follow the standard pattern[N] in the text maps to entry N in the reference list, and every reference is cited at least onceThe difference between a best practice and an enforced safeguard is that the safeguard runs regardless of time pressure, fatigue, or the clinician’s familiarity with the topic. A single broken DOI — one that links to an unrelated paper or a dead URL — can undermine the credibility of an entire literature review.
The evidence pipeline generates four output files for each search:
| File | Purpose |
|---|---|
*_Review.md |
Structured literature review in markdown, ready for editing |
*_Review.docx |
Formatted Word document via pandoc, with clickable DOI links |
*_References.yaml |
Machine-readable reference ledger with full metadata |
*_References.bib |
BibTeX file for direct Zotero import |
*_PMIDs.txt |
One PMID per line for Zotero bulk import |
Every reference is traceable back to the search that found it and the PubMed metadata that verified it. The markdown-first approach means the review is written as structured text and converted to .docx via pandoc. The YAML file preserves the full reference ledger in a machine-readable format that other skills can consume — for example, a protocol-reviewer skill can read the YAML directly instead of re-searching the literature. The .bib and PMIDs.txt files mean the clinician’s Zotero library stays in sync with the review’s references.
The skill is open source: literature-search on GitHub.
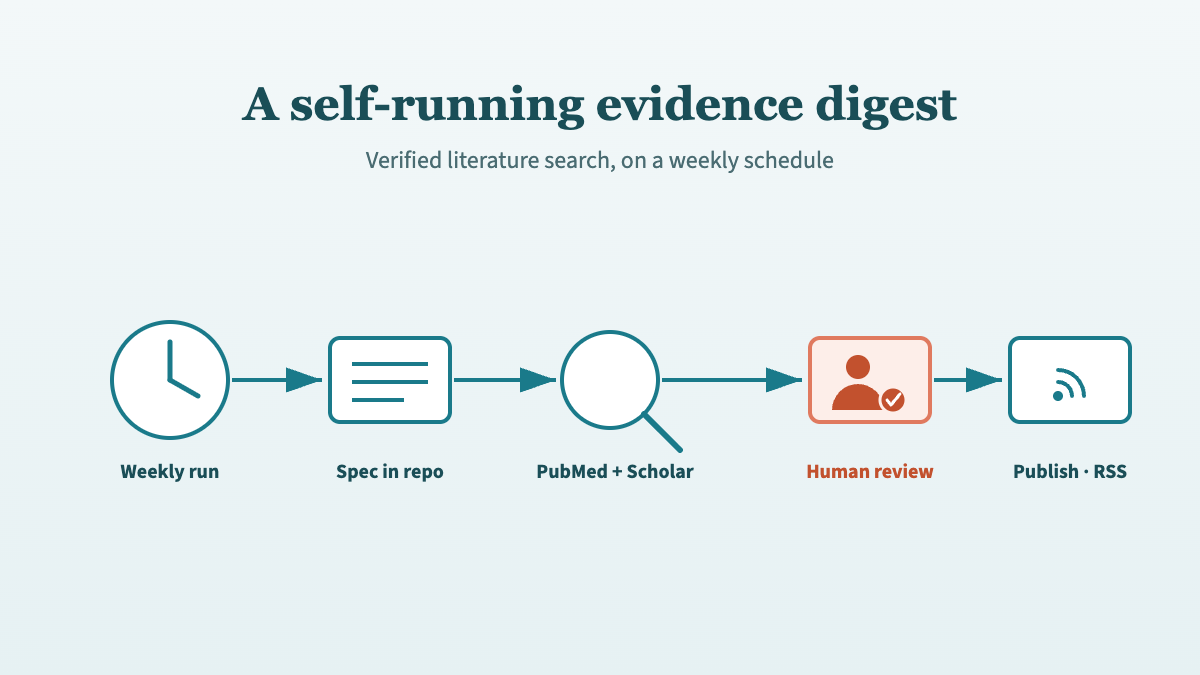
The same engine can run without a human starting each search. Kidney Watch puts this skill’s verified-citation approach on a weekly schedule, publishing an automated literature digest behind a pull-request review gate.
Clone the repository into your Claude Code skills directory:
git clone https://github.com/Laszlo75/literature-search \
~/.claude/skills/literature-searchYou will need Claude Code with the PubMed MCP and Scholar Gateway MCP connectors configured. Once installed, trigger the skill with natural language: “search for evidence on rituximab dosing in ABO-incompatible kidney transplantation.” See the repository README for full setup instructions and prerequisites.
No. This is for rapid evidence gathering, not formal systematic reviews. Systematic reviews follow PRISMA guidelines with pre-registered protocols and exhaustive search strategies. This skill provides rigorous, verified literature search for practical clinical questions — synthesising current evidence on a topic with full source traceability. The average systematic review takes 67.3 weeks (Borah et al., 2017); this skill completes an evidence gathering cycle in 15–30 minutes.
The dual-search architecture — structured keyword search plus semantic full-text search — is model-agnostic in principle. The current implementation uses Claude’s MCP ecosystem (PubMed connector and Scholar Gateway), but the core pattern applies regardless of which LLM you use: separate search from generation, build references from retrieved metadata, verify every citation before output.
The skill retrieves full text only for open-access papers available through PubMed Central. For paywalled papers, it falls back to the abstract from get_article_metadata plus any relevant passages Scholar Gateway retrieved from indexed full text. This combination usually provides enough information to assess relevance and quality, though it limits methodology appraisal for some papers.
When tested on GPT-4o, 56% of AI-generated medical citations were fabricated or contained errors (Linardon et al., JMIR Mental Health, 2025), and 64% of fabricated DOIs linked to real but unrelated papers. In clinical governance, a single fabricated reference can invalidate an entire review and erode trust in AI-assisted workflows. The ledger takes seconds to build during the search phase and prevents the most damaging failure mode. It is the minimum viable safeguard, not overkill.
Every review document includes a mandatory transparency disclaimer disclosing AI involvement. The reference ledger provides a complete audit trail: every citation maps to a specific PMID retrieved during the search phase and verified against PubMed metadata. The skill cannot cite a paper it did not retrieve, and it cannot fabricate a DOI. This makes the output auditable, reproducible, and defensible.
@online{szabo2026,
author = {Szabo, Laszlo},
title = {From Manual Search to Automated Evidence Pipeline},
date = {2026-04-04},
url = {https://lszabo.me/posts/literature-review-skill/},
langid = {en}
}