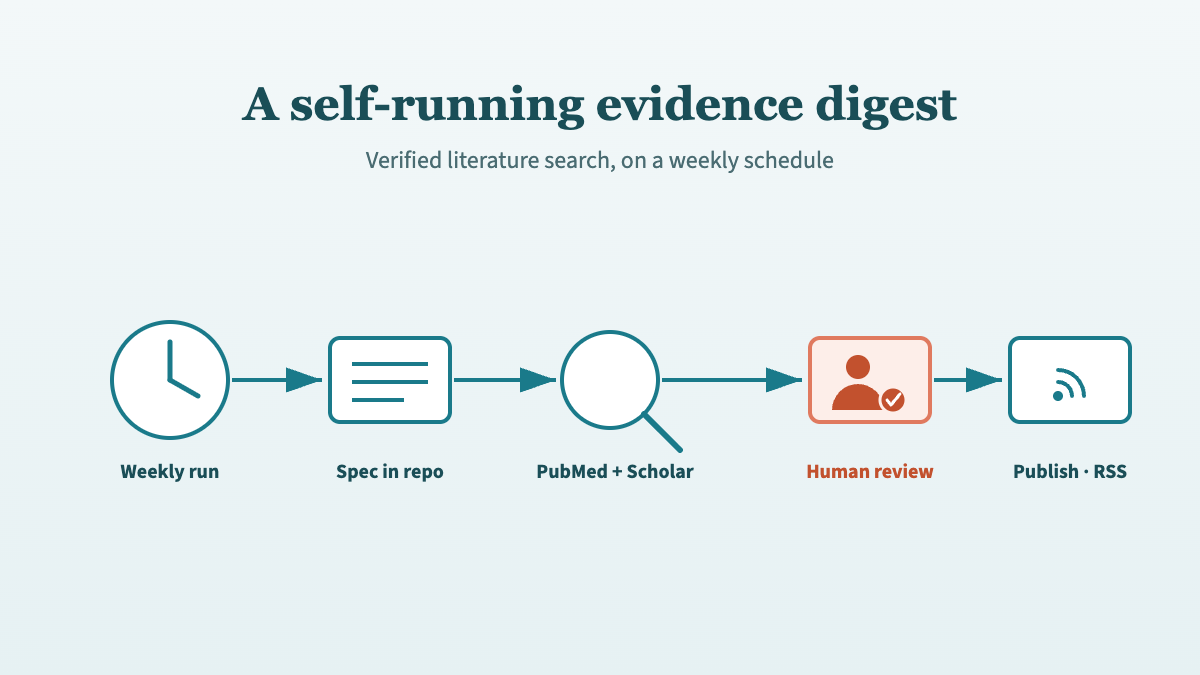
How to connect Claude to PubMed (step-by-step setup)
Set up the PubMed connector in Claude for verified medical literature search — enable it, query it, and check every PMID so citations are real, not hallucinated.
Jun 22, 2026
Laszlo Szabo 

So I finally did it. After years of thinking “I should really have a website,” here it is. Built with Quarto and R, because if I’m going to procrastinate on something, I might as well learn a new tool while doing it.
By day, I’m a transplant surgeon in Cardiff. By night (and the occasional weekend), I’m increasingly obsessed with data science, R, and finding better ways to answer clinical questions with code rather than gut feeling. More recently, I’ve become equally obsessed with AI, particularly Claude. It has quietly worked its way into how I search the literature, draft SOPs and policy documents, write code, and even plan my week. This site is where all of those worlds collide.
It started with a spreadsheet. I was trying to answer a straightforward question about kidney transplant outcomes at our unit, and the data lived in six different systems, none of which talked to each other. I spent a weekend manually copying numbers into Excel, making pivot tables, and cursing every time I realised I had missed a column.
There had to be a better way. Someone pointed me towards R. I installed RStudio, opened a blank script, and spent the next three hours failing to read a CSV file. But when I finally got it working, that first ggplot output felt like a small revelation. I could see patterns in our transplant data that had been invisible in the spreadsheet. I was hooked.
Since then, R has become my tool of choice for anything involving clinical data: building datasets for research projects, exploring outcomes, generating reproducible reports. The code does not lie, it does not forget a filter, and it runs the same way every time. That matters when you are making decisions about organ allocation.
I plan to write about things I find genuinely interesting, which, fair warning, mostly involves organ transplantation and wrangling data in R. Topics will include:
I’ll try to post regularly. Whether that means weekly or “whenever I have a spare evening” remains to be seen. Transplant surgery has a habit of rearranging your calendar at short notice.
I wanted something I could write in plain text, render with R code, and publish without fighting a CMS. Quarto ticks all those boxes, and it does a few things that matter specifically for academics:
.qmd file I can version-control with Git. The entire source is on GitHub.If you are thinking of building your own academic site, these resources got me started:
The bit I’m most pleased with is the data-driven CV. Six CSV files in a data/ folder contain my education, work history, qualifications, roles, research projects, and skills. Three different pages read those same CSVs and render them in different formats: an HTML timeline CV, a clean publications page parsed from my Zotero bibliography, and a PDF CV for download. One source of truth, zero manual duplication.
It is a small thing, but it solves a real problem. Every academic has had the experience of updating their CV in one place and forgetting to update it in three others. This approach makes that impossible.
Right, that is enough for a first post. Time to go and actually write something worth reading.